A Scrapy egy, a Pythonban kifejlesztett nyílt forráskódú keretrendszer, amely lehetővé teszi webes "pókok" vagy bejárók létrehozását az információk weboldalakról történő gyors és egyszerű kinyerése érdekében.
Ez az útmutató bemutatja, hogyan hozhat létre és futtathat webes pókot a Scrapy alkalmazással a kiszolgálón az információk weboldalakról történő kinyerése érdekében különböző technikák segítségével.
Először csatlakozzon a szerverhez SSH kapcsolaton keresztül. Ha még nem tette meg, akkor ajánlott átböngésznie a Hogyan javítható az SSH biztonság az Ubuntu 18.04-en? útmutatónkat a folyamat megkezdése előtt. Helyi szerver esetén folytassa a következő lépéssel, és nyissa meg a szerver terminált.
A virtuális környezet létrehozása
A tényleges telepítés megkezdése előtt folytassa a rendszercsomagok frissítésével:
Folytassa a működéshez szükséges néhány függőség telepítésével:
$ sudo apt-get install python-dev python-pip libxml2-dev zlib1g-dev libxslt1-dev libffi-dev libssl-dev
A telepítés befejezése után megkezdheti a virtualenv, egy Python csomag konfigurálását, amely lehetővé teszi a Python csomagok telepítését elszigetelt módon, más szoftverek veszélyeztetése nélkül. Bár nem kötelező, a Scrapy fejlesztői ezt a lépést erősen ajánlják:
$ sudo pip install virtualenv
Ezután készítsen egy könyvtárat a Scrapy környezet telepítéséhez:
$ sudo mkdir /var/scrapy
$ cd /var/scrapy
És inicializálja a virtuális környezetet:
$ sudo virtualenv /var/scrapy
New python executable in /var/scrapy/bin/python
Installing setuptools, pip, wheel...
done.
A virtuális környezet aktiválásához futtassa a következő parancsot:
$ sudo source /var/scrapy/bin/activate
A "deaktiválás" paranccsal bármikor kiléphet.
A Scrapy telepítése
Most telepítse a Scrapy alkalmazást, és hozzon létre egy új projektet:
$ sudo pip install Scrapy
$ sudo scrapy startproject example
$ cd example
Az újonnan létrehozott projektkönyvtárban a fájl a következő felépítésű lesz:
example/
scrapy.cfg # configuration file
example/ # module of python project
__init__.py
items.py
middlewares.py
pipelines.py
settings.py # project settings
spiders/
__init__.py
A shell használata tesztelési célokra
A Scrapy lehetővé teszi a weboldalak HTML-tartalmának letöltését és az információk extrapolálását különböző technikák, például css választók segítségével. Ennek a folyamatnak a megkönnyítése érdekében a Scrapy egy "shellt" biztosít az információk kinyerésének valós időben történő teszteléséhez.
Ebben az oktatóanyagban megtudhatja, hogyan nyerheti ki el az első bejegyzést a Reddit főoldaláról:
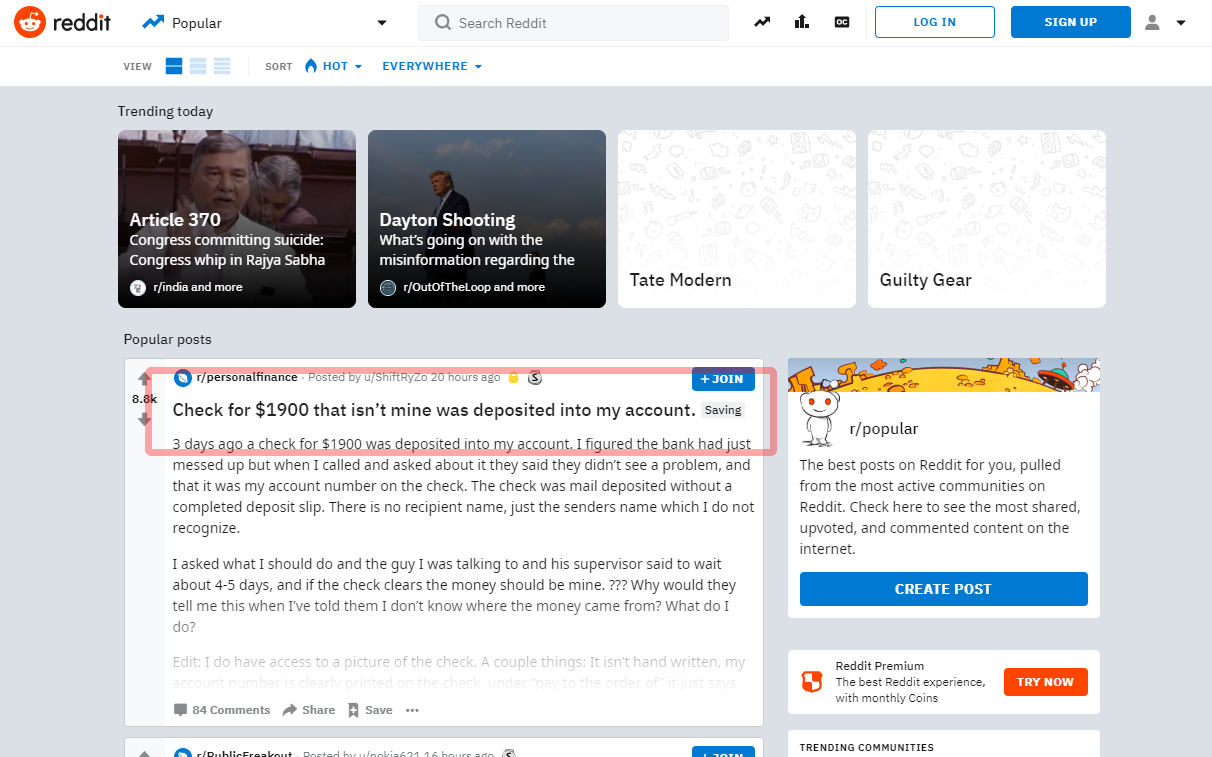
Mielőtt továbbmenne a forrás írására, próbálja meg kibontani a címet a shellen keresztül:
$ sudo scrapy shell "reddit.com"
Néhány másodpercen belül a Scrapy letölti a fő oldalt. Tehát írja be a parancsokat a ’response’ objektummal. Ahogy a következő példában, használja a "article h3 :: text": választót, hogy megkapja az első bejegyzés címét.
>>> response.css('article h3::text')[0].get()
Ha a választó megfelelően működik, a cím jelenik meg. Ezután lépjen ki a shellből:
Új pók létrehozásához hozzon létre egy új Python fájlt a példa / spiders / reddit.py projektkönyvtárban:
import scrapy
class RedditSpider(scrapy.Spider):
name = "reddit"
def start_requests(self):
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)
def parseHome(self, response):
headline = response.css('article h3::text')[0].get()
with open( 'popular.list', 'ab' ) as popular_file:
popular_file.write( headline + "\n" )
Minden pók örökli a Scrapy modul Spider osztályát, és a start_requests módszerrel indítja el a kéréseket:
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)
Amikor a Scrapy befejezte az oldal betöltését, meghívja a visszahívási funkciót (self.parseHome).
A válaszobjektum birtokában a kiszemelt tartalom elfogható:
headline = response.css('article h3::text')[0].get()
Kipróbálási célokra mentse el egy "popular.list" fájlba.
Indítsa el az újonnan létrehozott pókot a következő paranccsal:
$ sudo scrapy crawl reddit
A befejezés után az utolsó kibontott cím megtalálható a popular.list fájlban:
A Scrapyd ütemezése
A pókok végrehajtásának ütemezéséhez használja a Scrapy "Scrapy Cloud" által kínált szolgáltatást (lásd: https://scrapinghub.com/scrapy-cloud), vagy telepítse a nyílt forráskódú daemont közvetlenül a szerverére.
Győződjön meg róla, hogy a korábban létrehozott virtuális környezetben van, és telepítse a scrapyd csomagot a pip segítségével:
$ cd /var/scrapy/
$ sudo source /var/scrapy/bin/activate
$ sudo pip install scrapyd
A telepítés befejezése után készítsen elő egy szolgáltatást az /etc/systemd/system/scrapyd.service fájl létrehozásával a következő tartalommal:
[Unit]
Description=Scrapy Daemon
[Service]
ExecStart=/var/scrapy/bin/scrapyd
Mentse el az újonnan létrehozott fájlt, és indítsa el a szolgáltatást a következő módon:
$ sudo systemctl start scrapyd
Mostantól a daemon konfigurálva van, és készen áll az új pókok fogadására.
A például szolgáló pók telepítéséhez a Scrapy által biztosított „scrapyd-client” nevű eszközt kell használni. Folytassa a telepítést a pip segítségével:
$ sudo pip install scrapyd-client
Folytassa a scrapy.cfg fájl szerkesztésével és a telepítési adatok beállításával:
[settings]
default = example.settings
[deploy]
url = http://localhost:6800/
project = example
Most pedig telepítse a parancs futtatásával:
A pók végrehajtásának ütemezéséhez egyszerűen hívja meg a scrapyd API-t:
$ sudo curl http://localhost:6800/schedule.json -d project=example -d spider=reddit